Mastering Reinforcement Learning: A Comprehensive Guide
Written on
Chapter 1: Introduction to Reinforcement Learning
Reinforcement Learning (RL) is an innovative approach that enables an agent to learn how to navigate an environment through trial and error. If you're curious about how to leverage RL to excel at a game, continue reading...
The core objective is to train an RL agent that explores the game environment by interacting with it. The agent discovers which actions in various states will lead to the highest long-term rewards. Once it has developed an optimized policy—essentially a strategy for decision-making—the agent becomes adept at maximizing rewards, allowing it to tackle the game like an expert.
The comprehensive process of training an agent using RL can be broken down into several key steps:
- Define the objective
- Initialize the environment
- Engage with the environment
- Discover an optimal policy
- Implement the optimal policy
Section 1.1: Defining the Objective
The initial step in deploying RL involves clarifying the agent's objective and grasping the environment it will operate in. This includes outlining the specific goals and desired outcomes while understanding the state space, action space, and reward function of the environment.
Following this, it's essential to create a simulated environment for the agent's interactions. This can be achieved through custom environments or simulation tools like OpenAI Gym, which accurately reflect real-world scenarios and provide essential data for the agent's decision-making.
Defining clear objectives and constructing an effective simulated environment are pivotal for successful RL application.
Section 1.2: Initializing the Agent’s Policy
Next, the agent's policy is initialized with random values. This policy will evolve as the agent engages with the environment and learns the optimal strategy via trial and error.
Reinforcement Learning in 3 Hours | Full Course using Python - YouTube: This video provides a comprehensive introduction to reinforcement learning concepts, guiding viewers through the intricacies of building a reinforcement learning model using Python.
Section 1.3: Engaging with the Environment
In RL, the agent learns through its interactions with the environment by taking actions in different states via exploration and exploitation.
The agent investigates the environment by experimenting with various actions and observing the resulting rewards. This process aids the agent in gathering valuable information while simultaneously exploiting its existing knowledge by opting for actions likely to yield the highest rewards. Striking a balance between exploration and exploitation is crucial for the agent's learning process.
Exploration involves the agent testing new actions to collect information and enhance its understanding, while exploitation focuses on leveraging current knowledge to maximize rewards.
Section 1.4: Discovering an Optimal Policy
As the agent engages with the environment, it updates its policy and value estimates based on the rewards observed from various states. The ultimate goal is to identify an optimal policy that guides the agent in making decisions that maximize cumulative rewards.
An optimized policy is vital for the agent's success in RL, allowing it to make informed decisions that enhance its performance.
Finding an optimal policy involves two intertwined processes: Policy Evaluation (PE) and Policy Improvement (PI). PE estimates the value of a given policy, while PI updates the policy to enhance its effectiveness. Collectively, these processes are known as Generalized Policy Iteration.
To achieve an optimal policy, the agent must navigate the exploration-exploitation dilemma. A common strategy is the ε-greedy policy, which randomly chooses between exploration and exploitation. This method allows the agent to explore various parts of the environment while also exploiting its knowledge to maximize expected rewards.
Chapter 2: Applying the Optimized Policy
Once the agent has trained adequately and developed an optimized policy, it can now use this policy to engage with the game and fulfill its designated tasks.
It’s important to remember that both the environment and the objectives may evolve over time. Consequently, you might need to retrain the agent to adapt to new circumstances or enhance its performance.
End To End Machine Learning Project Implementation With Dockers, GitHub Actions And Deployment - YouTube: This video covers the complete implementation process for a machine learning project, including deployment strategies and best practices.
Section 2.1: End-to-End Code Implementation for CartPole-v1
For the CartPole challenge, the agent will be trained using Q-Learning.
Defining the Objective:
The CartPole-v1 task requires the agent to maintain balance by applying forces to move the cart left or right.
- Action Space: The agent can either:
- 0: Push cart to the left
- 1: Push cart to the right
- Observation Space:
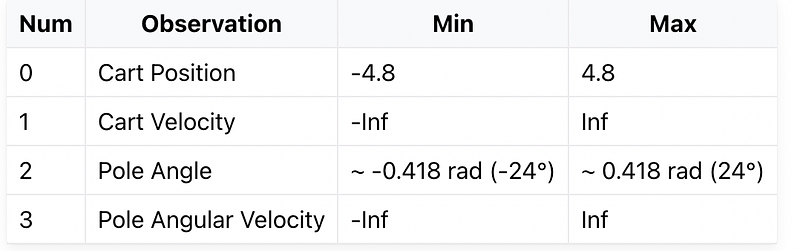
- Rewards: The agent earns a reward of +1 for each time step the pole remains upright, with a threshold of 500 for version 1.
Initializing the Agent's Policy:
A policy maps states to actions, shaping the agent's behavior within the environment. The goal of RL is to identify an optimized policy that maximizes cumulative rewards over time.
To do this, the agent’s policy is initialized with random values reflective of the state and action spaces.
# Create the environment
env = gym.make('CartPole-v1')
# Define the state and action spaces
state_space = env.observation_space.shape[0]
action_space = env.action_space.n
# Initialize the agent's policy
policy = np.random.rand(state_space, action_space)
The CartPole task features four continuous states, which need to be discretized for effective Q-Learning application.
Discretizing the States:
Since Q-learning typically relies on discrete states, continuous states must be divided into manageable categories. This approach enables the algorithm to function efficiently.
The following function bins the continuous space into discrete segments based on predefined boundaries:
def convert_state_discrete(obs):
# Creating 10 bins for cart position, pole angle, cart velocity, and pole angular velocity
cart_position_bins = pd.cut([-2.4, 2.4], bins=10, retbins=True)[1][1:-1]
pole_angle_bins = pd.cut([-2, 2], bins=10, retbins=True)[1][1:-1]
cart_velocity_bins = pd.cut([-1, 1], bins=10, retbins=True)[1][1:-1]
angle_rate_bins = pd.cut([-3.5, 3.5], bins=10, retbins=True)[1][1:-1]
# Discretizing the state
disc_state = int("".join(map(lambda feature: str(int(feature)), [np.digitize(x=[obs[0]], bins=cart_position_bins)[0],
np.digitize(x=[obs[1]], bins=pole_angle_bins)[0],
np.digitize(x=[obs[2]], bins=cart_velocity_bins)[0],
np.digitize(x=[obs[3]], bins=angle_rate_bins)[0]])))
discrete_states = list(map(int, str(disc_state)))
return tuple(discrete_states)
Thus, we modify the policy initialization:
policy = np.zeros((10,10,10,10) + (env.action_space.n,))
Engaging with the Environment to Find an Optimal Policy:
Here, we implement the Q-Learning algorithm to locate the optimal policy. The agent employs an ε-greedy policy to balance exploration and exploitation.

# Define the learning rate, exploration rate, and number of episodes
gamma = 0.01
alpha = 0.1
epsilon = 0.1
num_episodes = 10000
# Train the agent
for episode in range(num_episodes):
state = env.reset()
state = convert_state_discrete(state)
done = False
while not done:
if np.random.uniform(0,1) < epsilon:
action = env.action_space.sample()else:
action = np.argmax(policy[state])
next_state, reward, done, _ = env.step(action)
next_state = convert_state_discrete(next_state)
# Update the policy
policy[state][action] += alpha * (reward + gamma * np.max(policy[next_state]) - policy[state][action])
state = next_state
print('Training Completed')
Applying the Optimized Policy:
After sufficient training, the agent is equipped with an optimized policy and is ready to perform its tasks effectively.
num_episodes = 20
for episode in range(num_episodes):
state = env.reset()
steps = 1
done = False
episode_reward = 0
while not done:
steps += 1
env.render()
state = convert_state_discrete(state)
action = np.argmax(policy[state])
state, reward, done, _ = env.step(action)
episode_reward += reward
print("Reward: ", reward, "steps: ", steps, "episode: ", episode, "Total episode Reward: ", episode_reward)
env.reset()
env.close()
It’s essential to acknowledge that environments and goals can evolve, necessitating retraining of the agent to adapt to new challenges or to enhance its performance.

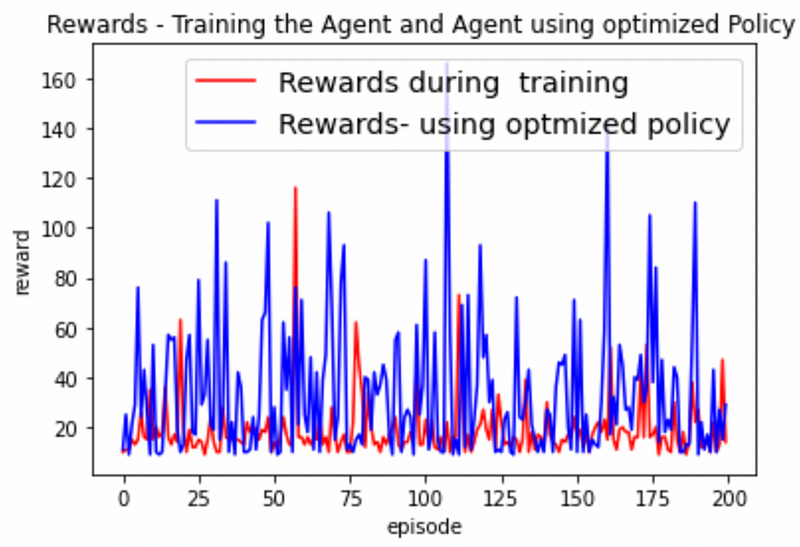
The graph illustrates the agent's improved performance after the application of the optimized policy. Performance can be further enhanced by:
- Providing the agent with additional experience through interaction to foster learning.
- Implementing more sophisticated algorithms such as Deep Q-Learning, A2C, or PPO.
- Employing a suitable exploration strategy to enable the agent to gather more valuable insights about the environment.
- Tuning hyperparameters, including the learning rate, discount factor, exploration rate, or epsilon.
Hyperparameter Tuning for Q-Learning
- Learning Rate (α): This parameter controls the update magnitude of the agent’s policy, typically set between 0 and 1. A high learning rate may lead to rapid convergence but can also overshoot the optimal policy.
- Discount Factor (γ): This dictates the significance of future rewards versus current rewards, also set between 0 and 1. A high value prioritizes future rewards, while a lower value emphasizes immediate rewards.
- Exploration Rate (ε): This influences the ε-greedy policy, determining the likelihood of the agent taking random actions instead of the action with the highest expected reward.
- Number of Episodes: This refers to the total interactions the agent has with the environment before concluding the training.
References:
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction.
- David Silver’s Reinforcement Learning Lecture Series.