Creating a Portable OCR Tool with Tess4J in Four Steps
Written on
Chapter 1: Introduction to OCR and Tess4J
In recent years, various industries have increasingly acknowledged the importance of data, leading many organizations to embrace digitization—transforming information into formats that computers can easily read. Although digitizing workplace information offers substantial advantages, the extraction of data from physical documents remains a significant barrier to achieving comprehensive computerization.
Fortunately, with the emergence of Optical Character Recognition (OCR) technologies, the costs associated with manual data extraction have considerably decreased. While different OCR engines exhibit various strengths and limitations in text extraction, this article will focus on Tesseract-OCR due to its open-source nature, robust community support, and extensive documentation. Previously, I have developed OCR-related projects using TesseractJS, a pure JavaScript implementation of Tesseract, as detailed in the following articles:
Building a Text-To-Speech Application Using Client-Side JavaScript
A blend of OCR technology (Tesseract.js) and the Web Speech API, complete with code implementation.
Creating an Image & PDF Text Extraction Tool Using Tesseract OCR with Client-side JavaScript
A combination of PDF.js and Tesseract.js, featuring a full code implementation.
Transitioning to a deeper exploration of Tesseract-OCR, I chose to use Tess4J, a Java wrapper for Tesseract.
Section 1.1: Preparing for Development
Before diving into the development of the text extraction tool, it is essential to gather all the necessary dependencies for the Java application.
Pre-requisites:
- Download the required .dll files: liblept1744.dll and libtesseract3051.dll.
- Download Lept4J-1.62.2-src.zip and extract liblept1744.dll from ./Lept4J/lib/win32-x86–64/.
- Download Tess4J-3.4.1-src.zip (version 3.4.1 will be used for this project) and extract libtesseract3051.dll from ./Tess4J/lib/win32-x86–64/.
- Set up a new Java application project in your preferred IDE (e.g., NetBeans IDE). The project structure should resemble the following:
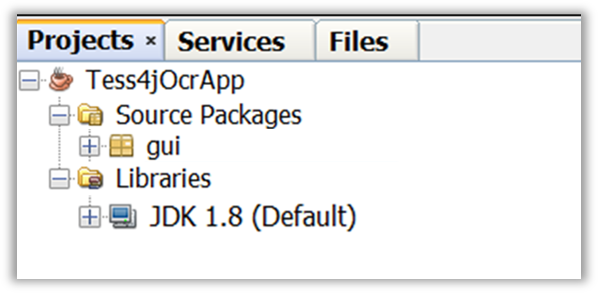
Section 1.2: Steps to Build the Application
The project name will be designated as Tess4jOcrApp. Here are the four steps to build the application:
Step 1: In the Tess4j folder, navigate to ./Tess4J/src, and copy both the com and net folders into your project via the IDE.
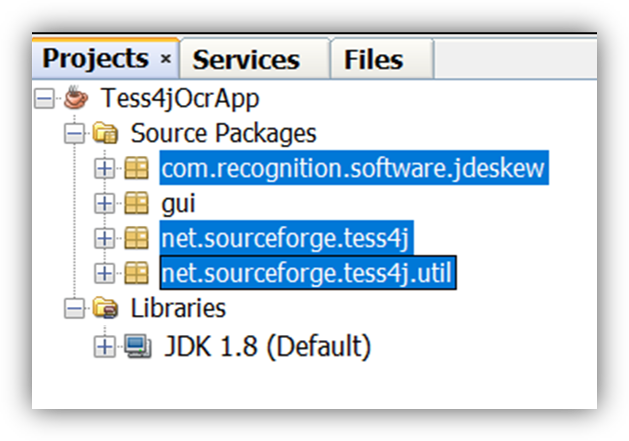
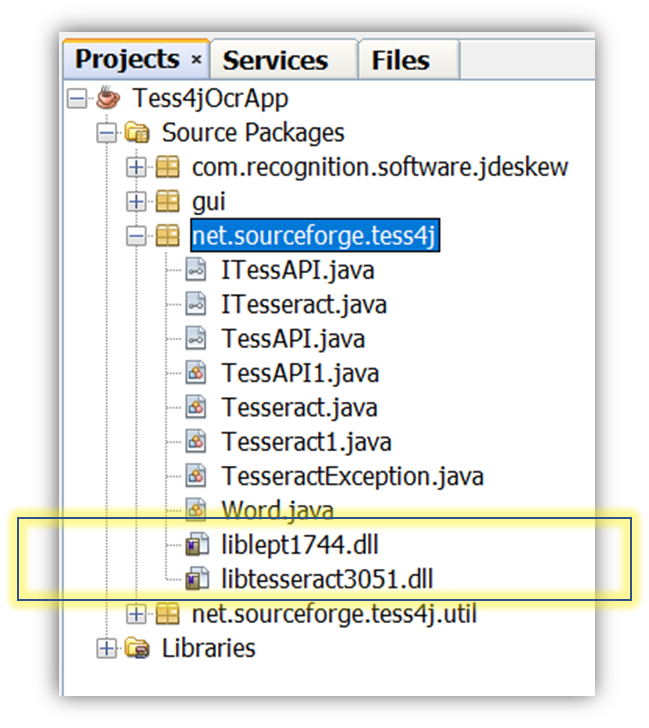
Step 2: Import the .dll files liblept1744.dll and libtesseract3051.dll into the package net.sourceforge.tess4j.
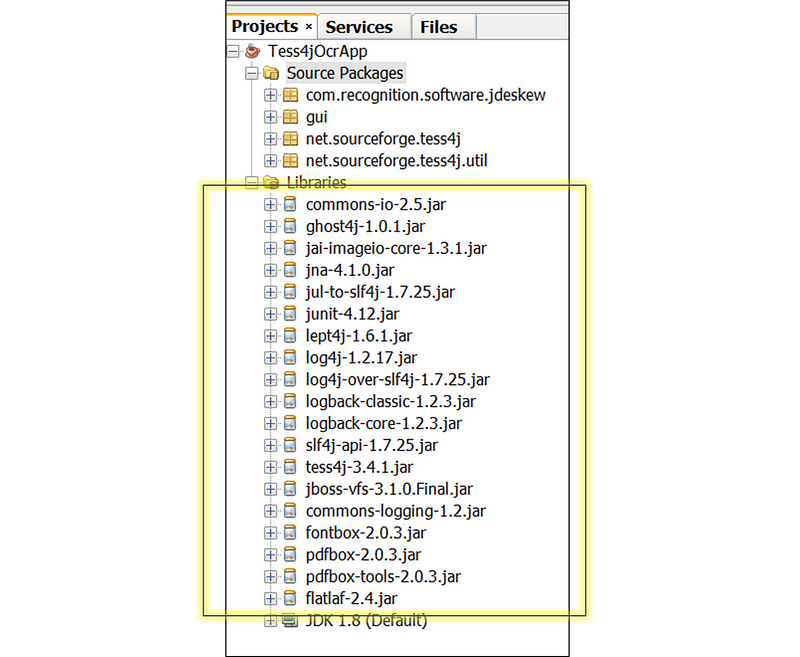
Step 3: Import JAR Dependencies — You have two options:
- Option 1: Retrieve JAR files from the original source at ./Tess4J/lib/*.jar and ./Tess4J/dist/tess4j-3.4.1.jar.
- Option 2: Download the consolidated list of JAR files from my GitHub repository at Tess4JOcrApp/tree/main/app/lib.
Step 4: Copy the tessdata folder from ./Tess4J/tessdata and paste it into your project’s working directory. This step is crucial for training the Tesseract ML model to recognize English characters.
To validate that the project setup is correct, run a few lines of code in the Main class to test the OCR functionality. This should include creating an instance of TesseractConfiguration with the datapath (tessdata) for Tesseract’s ML Model and invoking the primary function doOCR() with an input image file containing English text.
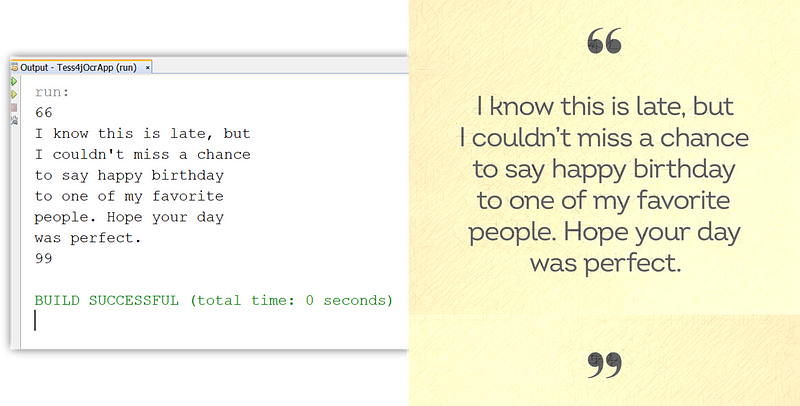
The results should demonstrate the application’s ability to identify all English characters in the input image, excluding punctuation and special characters.
At this point, the Image-to-Text Extraction Tool is complete and ready for use!
Chapter 2: Creating a User Interface for the OCR Tool
Having confirmed the code is functioning correctly, I opted to enhance the project by developing a Graphical User Interface (GUI) using Java Swing:
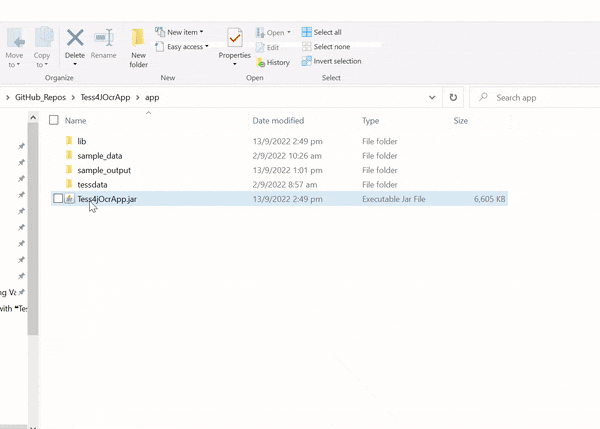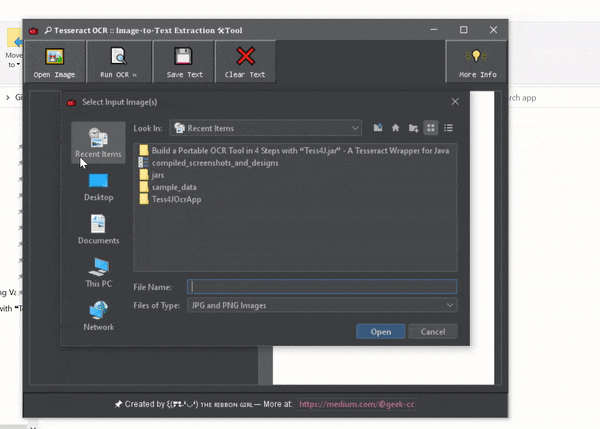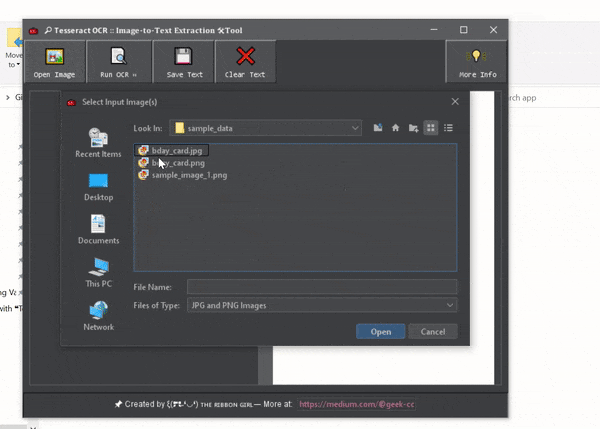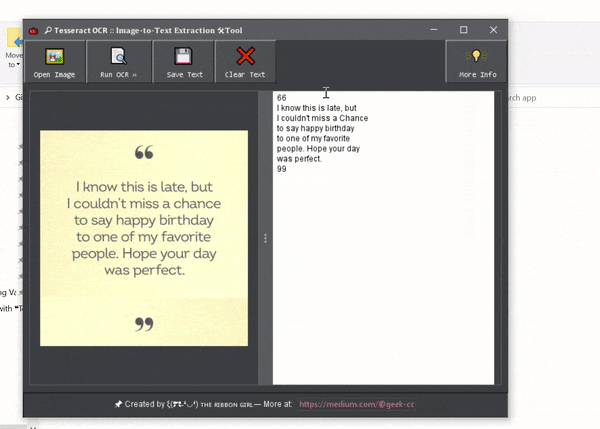
The complete source code is available on my GitHub repository at Tess4JOcrApp. Feel free to explore and contribute!
Personal Thoughts
While the integration of Tess4J’s OCR capabilities into the Java application was a success, it is important to note that other common input formats, such as PDF documents, have not been incorporated in this phase. Given the potential for further exploration with Tess4J, future developments will aim to handle not only image files but also PDF documents.
Thank you for sticking with me through this article! As I continue to work on Part II, please consider following me on Medium if you found this content helpful and want to stay updated on this ongoing project!
The first video, "How to use Tesseract OCR with Java? | Extract text from image," provides a thorough overview of using Tesseract OCR in Java applications.
The second video, "How to set up Tess4j in Eclipse," guides you through the setup process for using Tess4J in the Eclipse IDE.