Understanding Inception: Unpacking Parallel Convolutional Layers
Written on
Chapter 1: Introduction to Inception Architecture
In an earlier article, we explored the structure of AlexNet and built a sequential model based on its design. In this installment, we will delve deeper into the concept of multiple parallel convolutional layers, which enhance the model's capability to capture diverse features.
The video titled "Inception Net [V1] Deep Neural Network - Explained with Pytorch" provides an overview of the Inception architecture and its significance in deep learning.
Why Utilize Multiple Parallel Convolutional Layers?
Given the substantial variability in the positioning and size of elements within an image, employing various kernel sizes in convolutional layers becomes essential. Larger kernels help in capturing information that is more broadly distributed, while smaller kernels focus on more localized details. Constructing a sequential model with diverse kernel sizes often leads to a deep architecture that can be computationally intensive and prone to overfitting.
Utilizing multiple parallel convolutional layers is a strategic approach where several convolutional layers function simultaneously, each utilizing filters of different dimensions. This design enables the network to simultaneously extract features from various scales and positions within the image.
Traditionally, a convolutional neural network (CNN) employs a single layer with filters of uniform size (such as 3x3 or 5x5). These filters move across the image to identify specific patterns or features. In contrast, multiple parallel convolutional layers incorporate various filter sizes working concurrently. For instance, a layer might include filters of sizes 3x3, 5x5, and 7x7.
The Inception architecture, often referred to as GoogLeNet, stands out as a prominent example of a CNN that effectively utilizes parallel convolutional layers. This design significantly enhanced CNN performance across various image recognition tasks and laid the groundwork for numerous subsequent network architectures.
When feature maps from these parallel convolutions are combined, the Inception module concatenates them along the channel axis, resulting in a stacked tensor while retaining the height and width dimensions. For example, suppose we have three parallel convolutional layers within an Inception module, producing feature maps with these dimensions: - Layer 1: 28x28x64 - Layer 2: 28x28x128 - Layer 3: 28x28x256
After concatenation, the resultant tensor (feature map) will be: Combined Feature Map: 28x28x(64+128+256) = 28x28x448
By employing ‘same’ padding and a stride of 1 across each parallel convolution layer, the Inception module guarantees that all layers yield feature maps with identical height and width. This consistency is vital for successful channel concatenation, as differing spatial dimensions would impede the merging process.
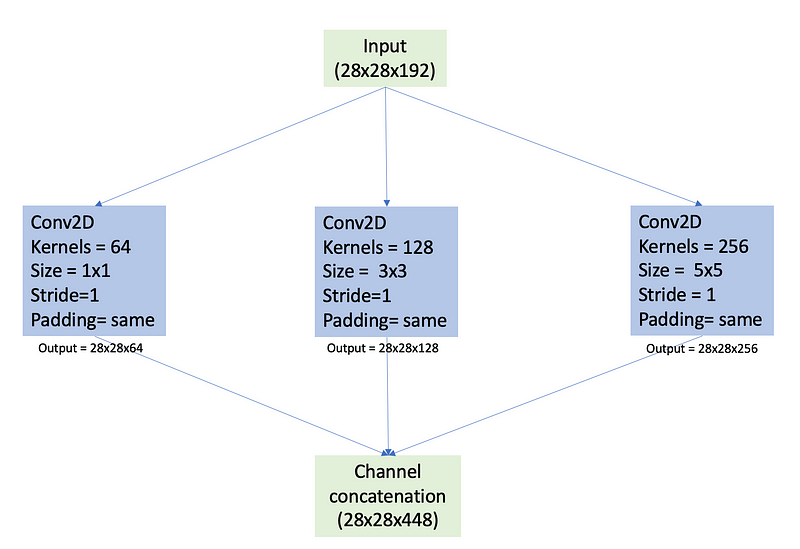
Parallel Convolutional Layers
Understanding Padding in CNNs
Padding is crucial for preserving spatial information and preventing data loss during the convolution process.
The video "Understanding the Architecture and Module of Inception Networks" further explains the role of padding and its significance in CNN architectures.
In addition to convolutional layers, some parallel paths may also include MaxPooling layers. These layers help reduce the spatial dimensions while retaining the most significant features derived from the input data. When MaxPooling layers are integrated, padding is added to ensure compatibility in shape for concatenation.
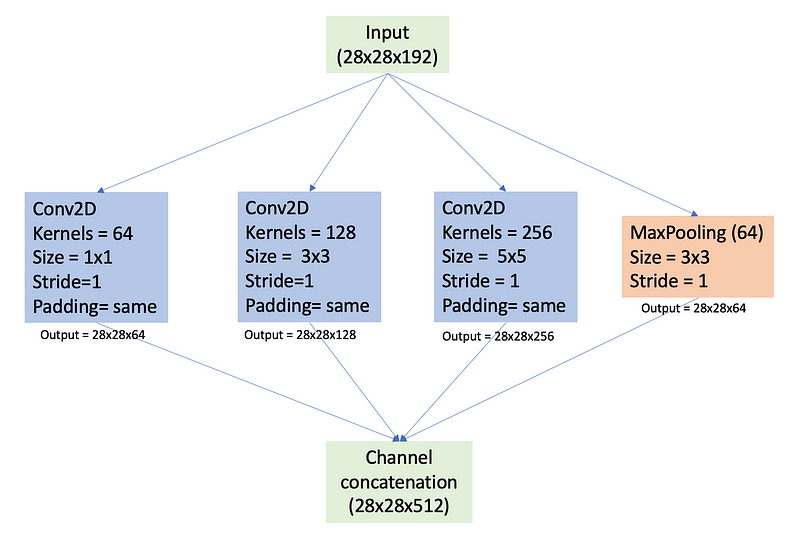
Parallel Convolutional Layers with MaxPooling Layer
Exploring the Purpose of 1x1 Convolutional Filters
As observed in the previous images, a convolution layer with a 1x1 kernel size is utilized. This might require a closer look if it went unnoticed! But what is the rationale behind using a 1x1 kernel?
In the architecture of Inception modules, 1x1 convolutions serve to diminish computational load and memory usage by reducing the number of channels. Let’s clarify this further.
Inception modules often include parallel convolutional layers with varying kernel sizes, leading to a rapid increase in the number of produced feature maps. Consequently, the channel count can escalate quickly with more parallel paths. This surge in channels can significantly heighten both computational and memory demands.
By integrating 1x1 convolutions, the Inception module can lower the channel count before feeding the data into larger kernel convolutions. Additionally, 1x1 convolutions excel in capturing correlations across channels (depth characteristics), while larger kernels are more adept at identifying spatial features. Inception modules typically apply 1x1 convolutions before larger convolutions (such as 3x3 or 5x5) and post-MaxPooling layers.
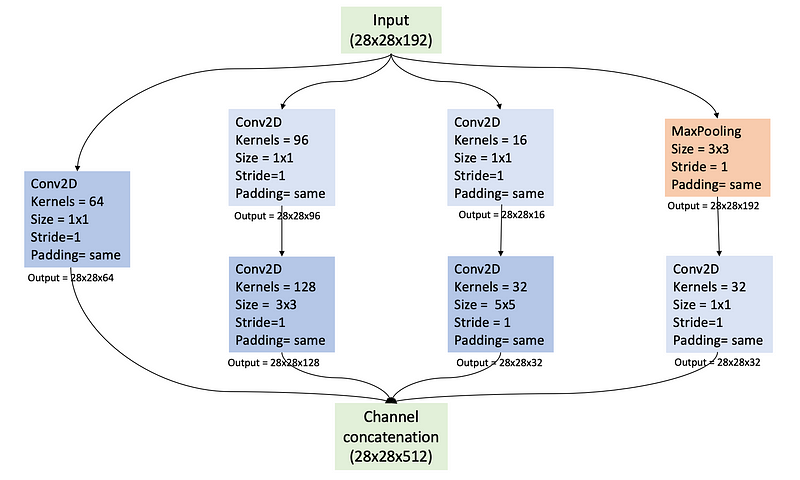
1x1 Convolutions Prior to 3x3 and 5x5 Filters
Auxiliary Classifiers: Enhancing Training Efficiency
An innovative feature introduced with the Inception architecture is the use of auxiliary classifiers. These additional branches are embedded within the network to provide intermediate predictions throughout the training phase. Positioned at various depths, these classifiers enable the model to generate predictions at multiple stages of feature extraction. They offer supplementary supervision signals that guide the training process and mitigate the vanishing gradient problem.
The configuration of auxiliary classifiers incorporates a mix of convolutional layers, pooling layers, and fully connected layers, culminating in a Softmax activation function tailored to the number of categories being classified. The number of auxiliary classifiers depends on the particular architecture employed.
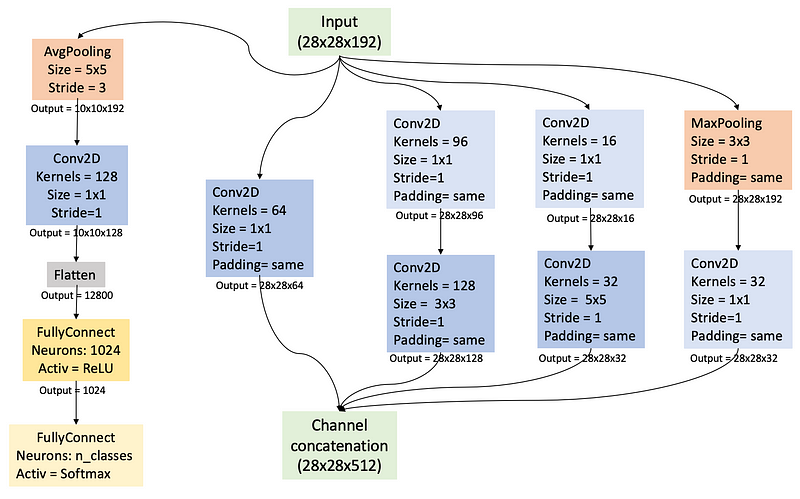
Auxiliary Classifiers
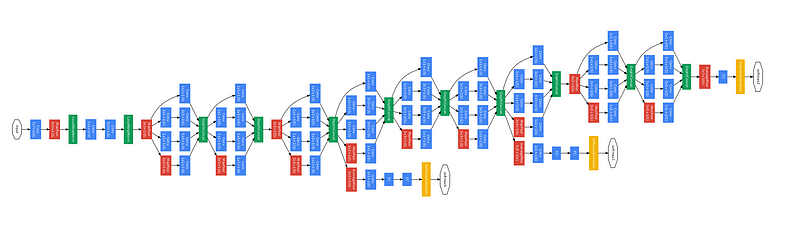
A Comprehensive View of the Inception Model
You can observe a complete Inception model in the following illustration.
Thank you for reading! Be sure to subscribe for notifications regarding my upcoming publications. If you enjoyed this article, please follow me to stay updated on new posts. For those interested in further exploration of this topic, consider my book "Data-Driven Decisions: A Practical Introduction to Machine Learning," which provides comprehensive insights into starting with machine learning. It's priced affordably, like a coffee, and supports my work!