Enhancing Image Generation Speed with Latent Consistency Models
Written on
Introduction
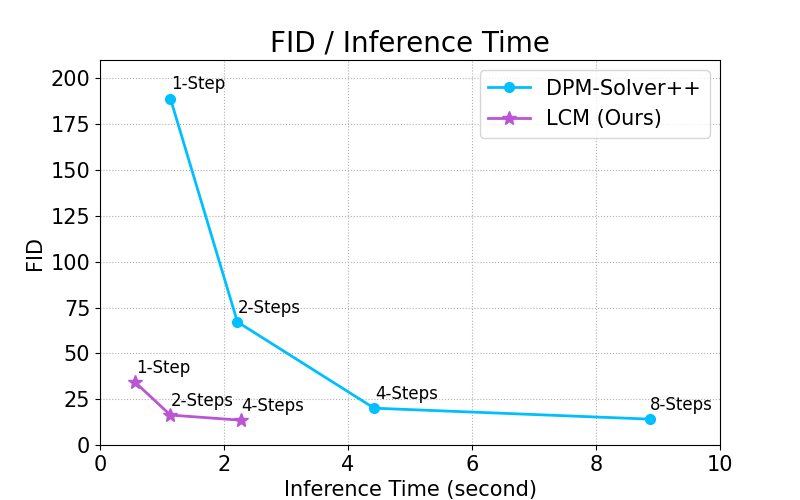
The speed of image creation using Stable Diffusion has long been a point of contention. Nevertheless, the introduction of LoRA through Latent Consistency Models (LCM) has transformed this experience by significantly expediting the process. LoRA effectively addresses the sluggish performance of traditional Latent Diffusion Models (LDM), allowing pre-trained models like Stable Diffusion to generate images in significantly fewer steps.
Advantages of Latent Consistency Models
Latent Consistency Models have made significant strides in enhancing image generation speed when compared to traditional techniques. A major advantage is how seamlessly this technology is integrated into the Stable Diffusion WebUI. Users can easily leverage their existing Checkpoints and Extensions while benefiting from faster results. To get started, download the LoRA version of LCM, available in both 1.5 and SDXL variations.
For ease of identification, rename the downloaded files from pytorch_lora_weights.safetensors to something more recognizable, such as LCM_LoRA_SD15 and LCM_LoRA_SDXL. After placing these files in the models/Lora directory, a quick refresh on the LoRA tab will make them accessible.
Testing the SD 1.5 Model
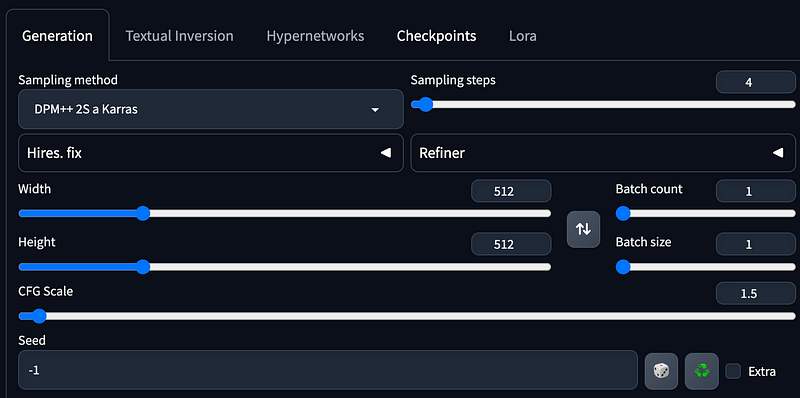
Begin your experience by testing the recommended settings. Notably, the Sampling Steps should be set to just 4, which may seem inadequate for generating an image, along with a very low CFP Scale of 1.5.

Basic Configuration
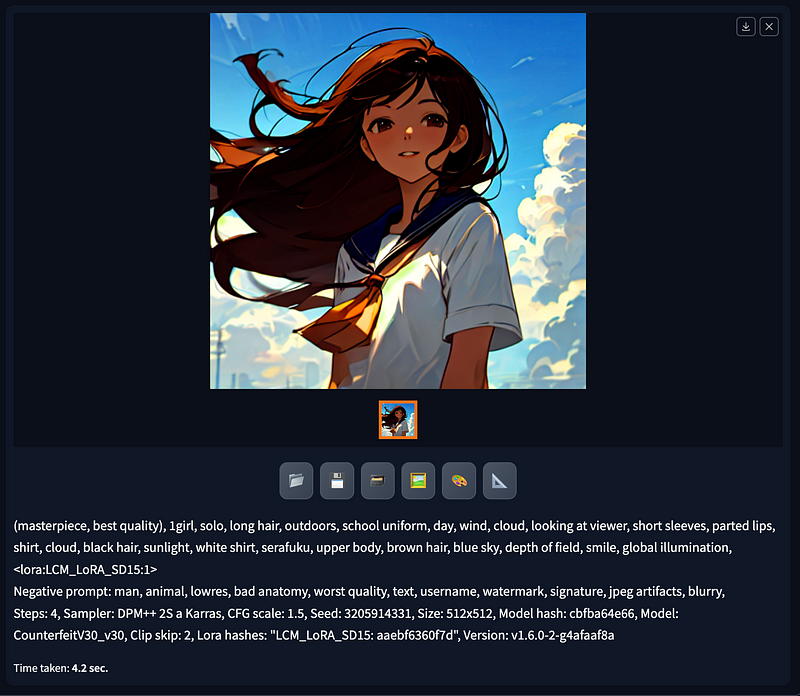
In this configuration, the prompt used is: (masterpiece, best quality), 1girl, solo, long hair, outdoors, school uniform, day, wind, cloud, looking at viewer, short sleeves, parted lips, shirt, cloud, black hair, sunlight, white shirt, serafuku, upper body, brown hair, blue sky, depth of field, smile, global illumination, <lora:LCM_LoRA_SD15:1>. The negative prompt includes: man, animal, lowres, bad anatomy, worst quality, text, username, watermark, signature, jpeg artifacts, blurry.
On a MacBook Pro M1 with 32GB of RAM, generating a 512 x 512 image in just four steps takes a mere 4.2 seconds.
Efficiency in Generation
With this remarkable speed, I was able to produce 12 images in a single minute to evaluate the effects. While the details may not be exceptionally intricate, the results are quite impressive for only four steps. So, what sets LoRA apart from conventional methods?
When utilizing LCM LoRA, the image begins to take shape by the fourth step, with additional details emerging by the tenth step. In contrast, without LoRA, the image remains blurry at the fourth step and only starts to form by the tenth step. However, it's important to note that using LoRA can sometimes distort the overall style due to the high weight settings, necessitating further tests to find the optimal balance.

Experimenting with Weight Settings
The differences in output can be quite distinct even with the same four-step completion when varying the weight settings. Higher weights tend to produce more noticeable style distortions. By keeping the weight between 0.4 and 0.6, users can achieve a balance between style retention and image completeness. Finding the right combination of steps and weights can lead to the best results.

In summary, experimenting with the balance between steps and weights is crucial for optimizing image generation performance in Stable Diffusion.
Chapter 2: Video Insights
This video discusses how to achieve a 1000% speed increase in Stable Diffusion image generation using a single technique.
Explore this video to learn how Stable Diffusion can be made up to 50% faster and what steps are involved.
Stay Connected
This article is published on Generative AI. Connect with us on LinkedIn for the latest AI news and insights. Let’s shape the future of AI together!
