Mastering DDPG Reinforcement Learning in PyTorch: A Comprehensive Guide
Written on
Overview of DDPG Implementation
This guide will walk you through creating an intelligent agent using the Deep Deterministic Policy Gradient (DDPG) algorithm, an advanced method in deep reinforcement learning.
Understanding the Mountain Car Environment
Key Concepts in Reinforcement Learning
- Fundamentals of Reinforcement Learning
- Temporal Difference Learning
- Q-Learning
- Deep Q Learning Techniques
- Introduction to Actor-Critic Methods
- Deep Deterministic Policy Gradient (DDPG) Explained
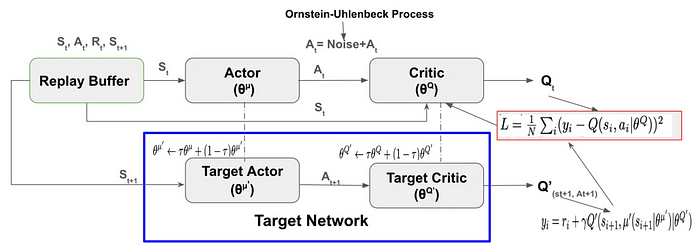
DDPG is a model-free, off-policy algorithm that employs the Actor-Critic method and is inspired by Deep Q-Networks. Its architecture includes:
- Replay Buffer
- Actor-Critic Neural Network
- Exploration Noise
- Target Network
- Soft Target Updates
Role of the Replay Buffer
The Replay Buffer is essential for storing transitions and rewards ( (S_t, A_t, R_t, S_{t+1}) ) collected during the agent's interaction with the environment. This component enhances learning speed and stabilizes the DDPG process by:
- Reducing sample correlation through diverse experiences.
- Facilitating off-policy learning by sampling from past experiences.
- Maximizing sample efficiency.
class ReplayBuffer:
"""
Reference:
Accepts tuples of (state, next_state, action, reward, done)
"""
def __init__(self, max_size=capacity):
"""Initialize the Replay Buffer."""
self.storage = []
self.max_size = max_size
self.ptr = 0
def push(self, data):
if len(self.storage) == self.max_size:
self.storage[int(self.ptr)] = data
self.ptr = (self.ptr + 1) % self.max_size
else:
self.storage.append(data)
def sample(self, batch_size):
"""Sample a batch of experiences."""
ind = np.random.randint(0, len(self.storage), size=batch_size)
state, next_state, action, reward, done = [], [], [], [], []
for i in ind:
st, n_st, act, rew, dn = self.storage[i]
state.append(np.array(st, copy=False))
next_state.append(np.array(n_st, copy=False))
action.append(np.array(act, copy=False))
reward.append(np.array(rew, copy=False))
done.append(np.array(dn, copy=False))
return np.array(state), np.array(next_state), np.array(action), np.array(reward).reshape(-1, 1), np.array(done).reshape(-1, 1)
Actor-Critic Neural Network Structure
The Actor-Critic framework involves two neural networks: an Actor and a Critic.
Actor Model:
- Input: Environment state
- Output: Continuous action
Critic Model:
- Input: Both the environment state and the action
- Output: Q-value representing the expected total reward for the state-action pair.
class Actor(nn.Module):
"""
The Actor model processes state observations to output an action.
"""
def __init__(self, n_states, action_dim, hidden1):
super(Actor, self).__init__()
self.net = nn.Sequential(
nn.Linear(n_states, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden1),
nn.ReLU(),
nn.Linear(hidden1, 1)
)
def forward(self, state):
return self.net(state)
class Critic(nn.Module):
"""
The Critic model estimates Q-values based on state-action pairs.
"""
def __init__(self, n_states, action_dim, hidden2):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(n_states + action_dim, hidden2),
nn.ReLU(),
nn.Linear(hidden2, hidden2),
nn.ReLU(),
nn.Linear(hidden2, hidden2),
nn.ReLU(),
nn.Linear(hidden2, action_dim)
)
def forward(self, state, action):
return self.net(torch.cat((state, action), 1))
Implementing Exploration Noise
Incorporating noise into the actions selected by the Actor is critical for encouraging exploration. Options include Gaussian noise or Ornstein-Uhlenbeck noise. The latter provides smoother fluctuations, enhancing exploration efficiency.
class OU_Noise:
"""Ornstein-Uhlenbeck process implementation."""
def __init__(self, size, seed, mu=0., theta=0.15, sigma=0.2):
self.mu = mu * np.ones(size)
self.theta = theta
self.sigma = sigma
self.seed = random.seed(seed)
self.reset()
def reset(self):
"""Reset the noise state to the mean."""
self.state = copy.copy(self.mu)
def sample(self):
"""Generate and return a new noise sample."""
dx = self.theta * (self.mu - self.state) + self.sigma * np.random.normal(size=len(self.state))
self.state += dx
return self.state
DDPG Algorithm Overview
DDPG utilizes two sets of Actor-Critic networks to approximate functions. The Target Network mirrors the Actor-Critic network but is updated more gradually through Soft Target updates, which enhance stability during training.
# Hyperparameters setup
capacity = 1000000
batch_size = 64
update_iteration = 200
tau = 0.001 # Soft update rate
gamma = 0.99 # Discount factor
directory = './'
hidden1 = 20 # Hidden layer size for Actor
hidden2 = 64 # Hidden layer size for Critic
class DDPG:
def __init__(self, state_dim, action_dim):
"""Initialize the DDPG agent."""
self.replay_buffer = ReplayBuffer()
self.actor = Actor(state_dim, action_dim, hidden1).to(device)
self.actor_target = Actor(state_dim, action_dim, hidden1).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=3e-3)
self.critic = Critic(state_dim, action_dim, hidden2).to(device)
self.critic_target = Critic(state_dim, action_dim, hidden2).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=2e-2)
self.num_critic_update_iteration = 0
self.num_actor_update_iteration = 0
self.num_training = 0
Training the Agent in the Mountain Car Environment
The following code demonstrates how to train the DDPG agent within the 'MountainCarContinuous-v0' environment, where the objective is for a car to reach the top of a mountain.
import gym
# Create the environment
env_name = 'MountainCarContinuous-v0'
env = gym.make(env_name)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Training parameters
max_episode = 100
max_time_steps = 5000
total_reward = 0
score_history = []
# Reproducibility
env.seed(0)
torch.manual_seed(0)
np.random.seed(0)
# Environment dimensions
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
# Instantiate the DDPG agent
agent = DDPG(state_dim, action_dim)
# Training loop
for i in range(max_episode):
state = env.reset()
for t in range(max_time_steps):
action = agent.select_action(state)
action = (action + np.random.normal(0, 1, size=action_dim)).clip(-max_action, max_action)
next_state, reward, done, _ = env.step(action)
agent.replay_buffer.push((state, next_state, action, reward, float(done)))
state = next_state
if done:
breakagent.update()
Testing the Trained DDPG Agent
After training, it's important to assess how well the agent performs in the environment.
test_iterations = 100
for i in range(test_iterations):
state = env.reset()
total_reward = 0
while True:
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
total_reward += reward
if done:
print(f"Episode {i}, Total Reward: {total_reward}")
break
state = next_state
Conclusion
The DDPG algorithm is a powerful off-policy Actor-Critic method suitable for continuous action spaces. It leverages a replay buffer and a target network to stabilize training. Achieving optimal performance requires careful tuning of hyperparameters, as even slight adjustments can significantly influence the algorithm's effectiveness.
Video Resources
To further enhance your understanding of DDPG, check out the following YouTube tutorials:
This video, titled "Reinforcement Learning in Continuous Action Spaces | DDPG Tutorial (Pytorch)", provides an in-depth exploration of DDPG.
The second video, "How to Implement Deep Learning Papers | DDPG Tutorial", walks you through implementing DDPG in a practical context.
References
- OpenAI's Spinning Up
- David Silver's Course
- Berkeley Deep RL
- Practical RL