Exploring Decoding Techniques in Natural Language Processing
Written on
Chapter 1: Understanding Decoding in NLP
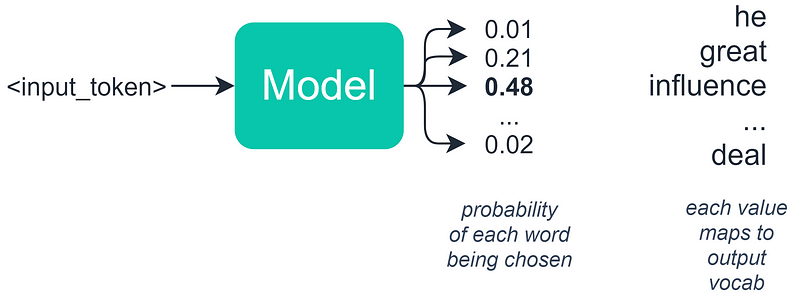
In the realm of natural language processing (NLP), one crucial yet often underestimated aspect of sequence generation is the selection of output tokens, commonly referred to as decoding. You might wonder how this selection is made—essentially, we choose tokens based on the probabilities assigned to them by our model.
While this is partially correct, it's important to note that in language-related tasks, we generally develop a model that produces a probability distribution for a set of potential tokens. At this juncture, it may seem logical to opt for the token with the highest probability. However, this approach can lead to unexpected issues, which we will explore further.
When generating machine-produced text, we have several methods to perform decoding, each offering different behaviors. In this article, we will examine three primary decoding techniques:
- Greedy Decoding
- Random Sampling
- Beam Search
Understanding how each of these methods operates is essential, as often, the solution to unsatisfactory outputs can be as simple as switching between these techniques. For those who prefer a visual explanation, I have created a video that covers all three methods in detail.
Additionally, I've provided a notebook for hands-on experimentation with each of these methods using GPT-2.
Section 1.1: Greedy Decoding
Greedy decoding is the simplest technique available. It takes the list of potential outputs and the already computed probability distribution, selecting the option with the highest probability (argmax). While this approach seems entirely rational and works well in many situations, it can lead to problems with longer sequences.
If you've encountered outputs that seem repetitive or nonsensical, it's likely due to greedy decoding getting stuck on a specific word or phrase and consistently assigning the highest probability to it.
Section 1.2: Random Sampling
The next technique we can utilize is random sampling. Similar to greedy decoding, random sampling relies on the probability distribution of potential outputs. This method randomly selects the next word based on its assigned probabilities.
For instance, if we have a probability distribution with words like "influence" at 48% and "great" at 21%, random sampling introduces an element of unpredictability. This randomness helps us avoid the repetitive cycles caused by greedy decoding. However, it can sometimes result in overly erratic outputs that lack coherence.
Section 1.3: Beam Search
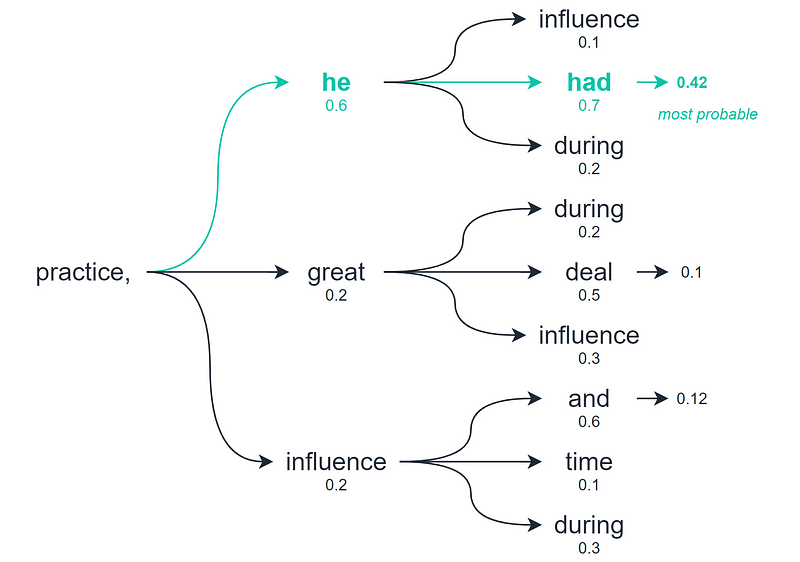
Beam search presents a more nuanced approach by examining multiple potential outputs before determining the best one. Unlike greedy decoding and random sampling, which focus only on the immediate next token, beam search assesses several tokens into the future, evaluating the overall quality of the sequences.
This method produces multiple potential output sequences, with the number of options determined by the number of "beams" being analyzed. However, beam search can also lead to repetitive sequences, similar to the issues seen in greedy decoding. To mitigate this, we can adjust the decoding temperature—a parameter that controls the randomness of the outputs. A default temperature of 1.0 can be elevated to 1.2 to enhance the variety and coherence of the generated text.
Chapter 2: Conclusion
To summarize, we have explored the three primary decoding methods for text generation in NLP: greedy decoding, random sampling, and beam search. Each technique has its strengths and weaknesses, and understanding these can significantly improve the quality of generated text.
If you have further questions or suggestions, feel free to reach out to me on Twitter or leave a comment below. Thank you for reading!
The second video titled "UMass CS685 S23 (Advanced NLP) #10: Decoding from language models" provides an in-depth analysis of decoding strategies in language models. This resource complements our discussion and offers additional insights into the topic.