Discovering the Power of Stable Video Diffusion in AI
Written on
Introduction to Stable Video Diffusion
Stability.ai has recently introduced its groundbreaking AI video model, Stable Video Diffusion (SVD), which is already making waves in the realm of video generation. This innovative model allows users to transform static images into dynamic videos, showcasing impressive results right out of the gate.

The remarkable capabilities of SVD have led many users to animate iconic memes using this new model. What sets SVD apart is its open-source nature, which not only makes it accessible but also positions it as a leading contender against other video generation models currently on the market.
Let's delve into how Stable Video Diffusion operates and how you can access it for free!
Showcase of Capabilities
The following videos, all derived from a single foundational image, demonstrate the capabilities of SVD.
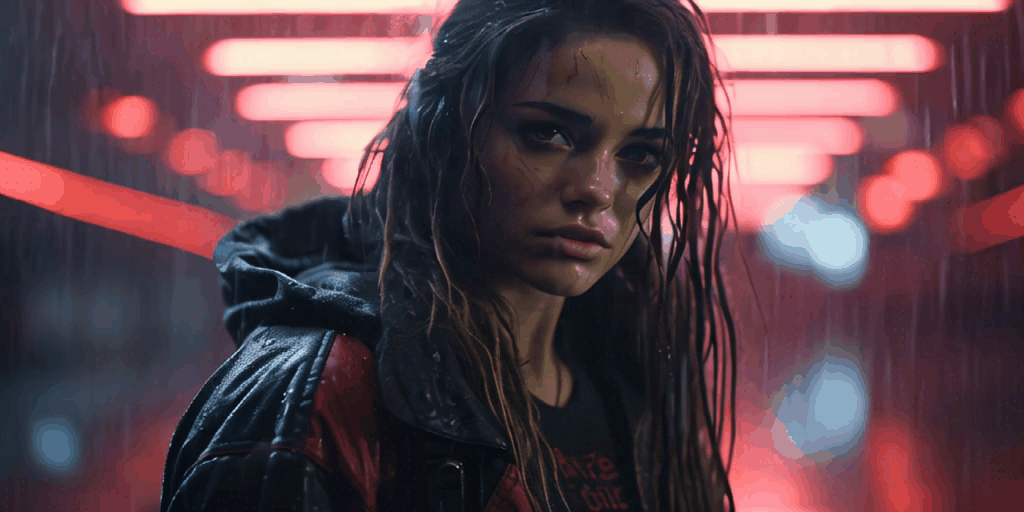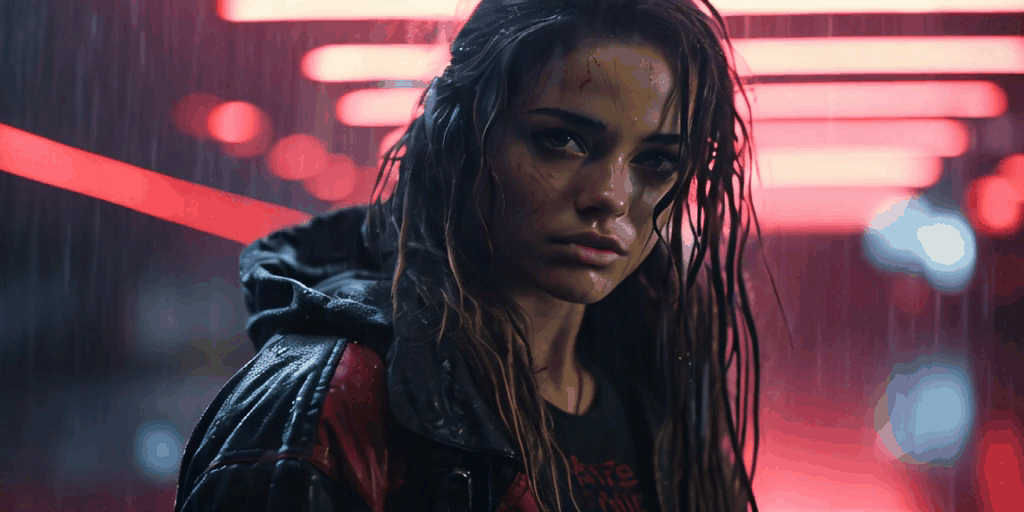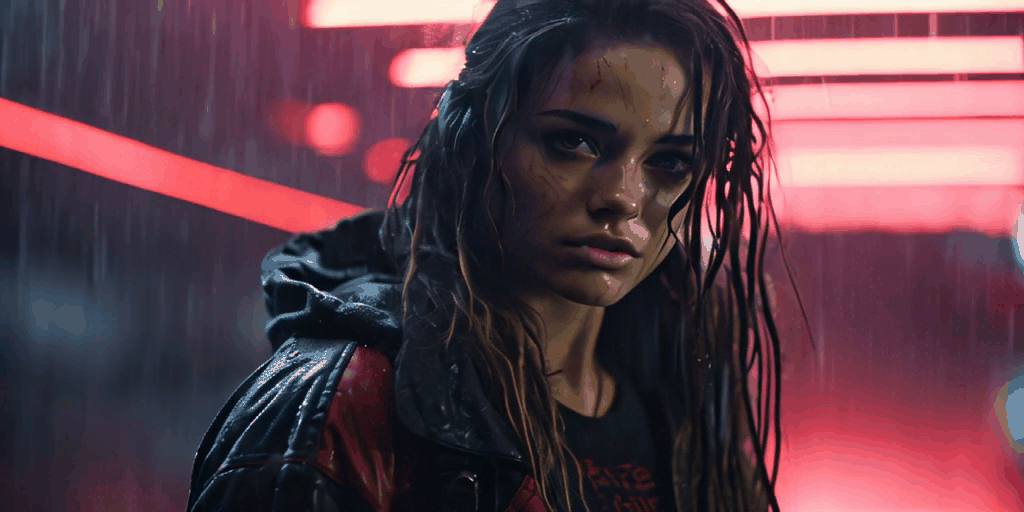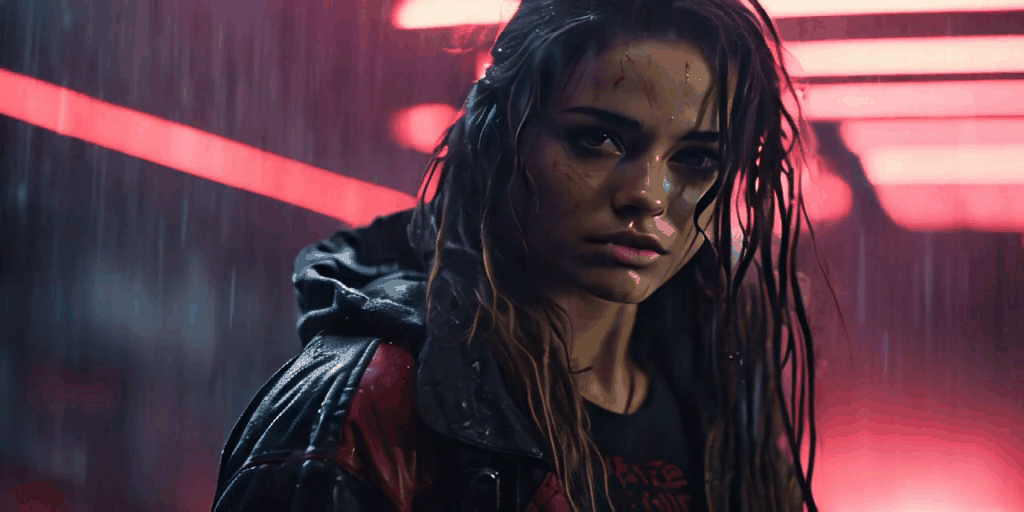

Currently, while SVD lacks the ability for users to control video creation through prompts or masks, this feature is anticipated to be available soon. The thriving Stable Diffusion community has already developed impressive workflows that have been incorporated into popular applications such as Adobe Photoshop.
Imagine the possibilities if features like ControlNet or Composer were integrated into an SVD framework!
Parameter Adjustments
Although control over video prompts is limited, users can still manipulate various settings to influence the results. Below are examples generated from the same base image, but with varying parameters (14fps and 25fps models, noise levels, and seed values):



Comparing Performance: SVD vs. Competitors
In the rapidly evolving field of AI video generation, RunwayML and Pika Labs have been frontrunners until now. However, recent evaluations indicate that SVD may surpass both of these competitors based on viewer feedback.
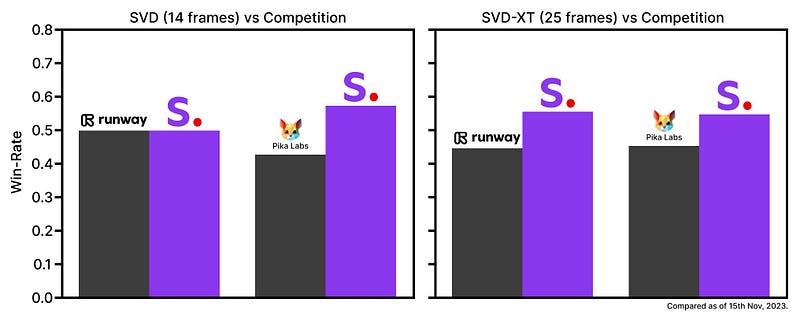
While SVD is available as an open-source project, it consists of two models: one for generating videos at 14 frames per second and another, SVD-XT, for 25 frames per second. Presently, both models are designated for personal experimentation only, with commercial use not permitted.
Utilizing Stable Video Diffusion
To begin working with Stable Video Diffusion, users have the option to download the model and run it on a local GPU, or, for those lacking suitable hardware, they can access the model through platforms like Replicate or Hugging Face. Below, you can find links to all three access points at the end of this article.
Both platforms feature user-friendly interfaces, but Replicate offers a broader array of options and parameters. Hugging Face is also popular, though it may have longer wait times.
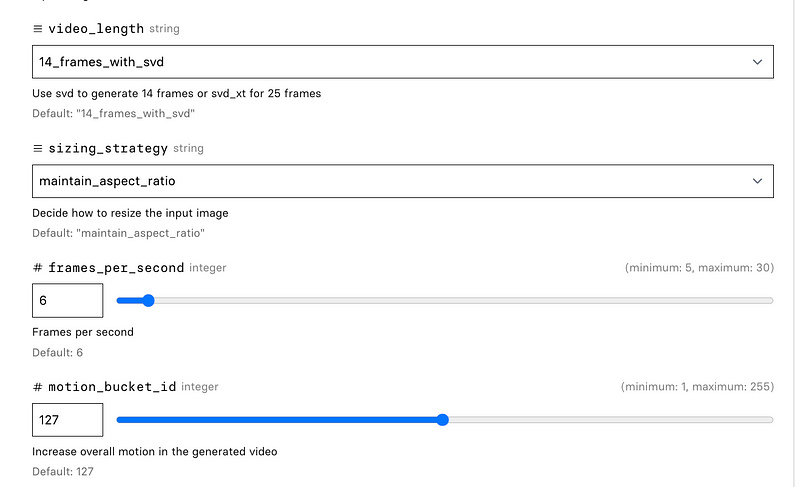
With the current Stable Video Diffusion interfaces, you can:
- Upload an image or capture one using a webcam.
- Select between the 14fps or 25fps models.
- Choose a resizing method (the model is trained on images sized 576x1024 pixels).
- Adjust motion bucket ID (higher values yield more motion in the generated video).
- Set seed values and more, including noise levels, decoding options, and custom frame rates.
Here’s how it appears on Replicate:
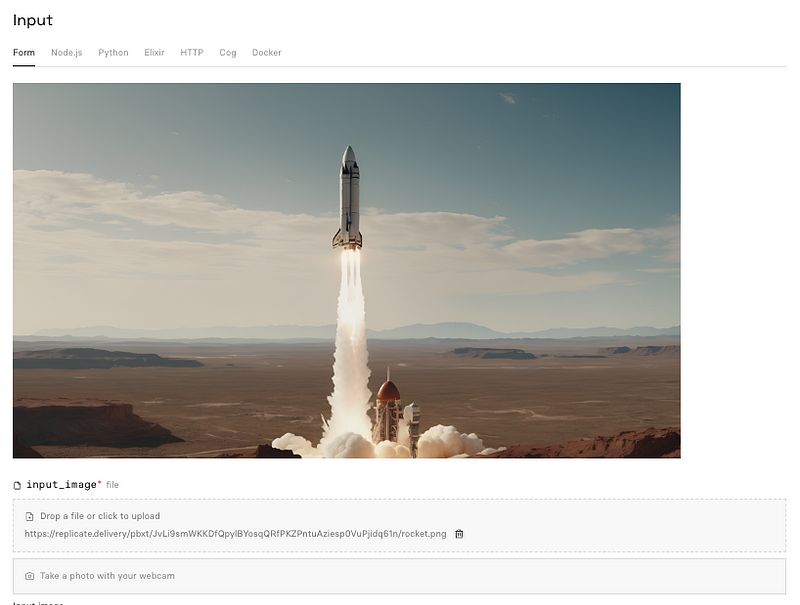
Once you hit “Run,” the model begins processing the video file. Experiment with the options to discover the optimal settings that bring your image to life.
Accessing Stable Video Diffusion
- Use Stable Video Diffusion @ Replicate
- Use Stable Video Diffusion @ Hugging Face
- Use Stable Video Diffusion @ GitHub
Additional Resources
- Stable Video Diffusion Blog Post
- Stable Video Diffusion Research Paper
Exploring the Best AI Video Generators
As we continue to explore the landscape of AI video generation, check out this insightful video comparing various models including Stable Video Diffusion, Runway, and Pika Labs.
Learn how to create AI videos using these tools in our next video segment.
If you find this content valuable, consider leaving a "clap" to help more people discover it!